Platform Quickstart
The thepi.pe platform provides a user-friendly interface for scraping and extracting data from various sources. This guide will walk you through the main features of the platform.
AI Model
All operations on the platform use Google Gemini 2.5 Flash Lite, a state-of-the-art vision-language model optimized for:
- Fast processing of documents and images
- High accuracy on complex layouts
- Support for multiple languages
- Understanding of charts, tables, and diagrams
- Excellent performance on structured data extraction
This model is automatically selected for all operations to ensure consistent, high-quality results across all your extractions.
Scraping
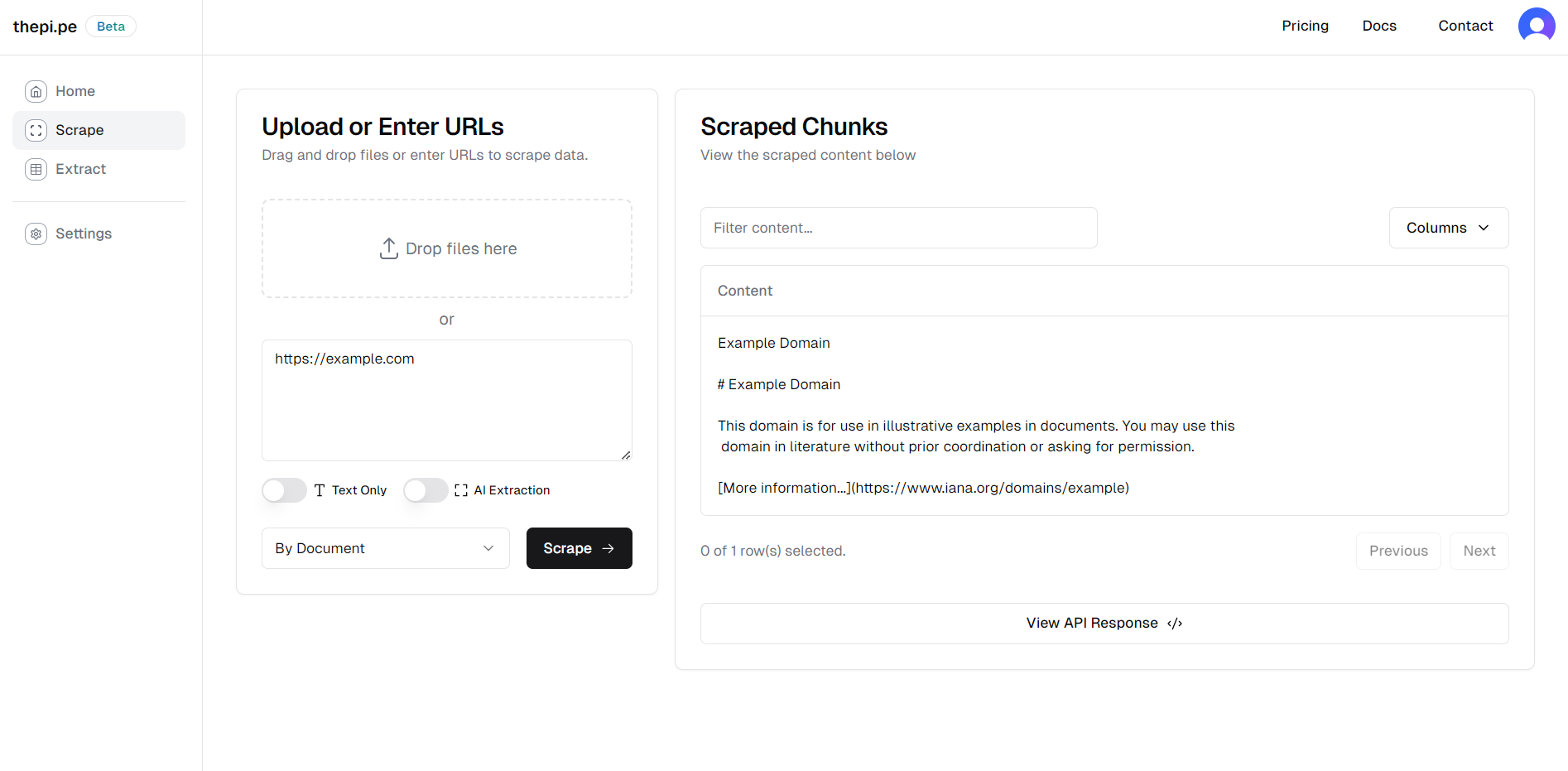
The scraping interface allows you to extract data from websites, PDFs, and other sources.
- Upload files or enter URLs in the designated area.
- Choose your scraping options:
- Text Only: Extract only text content
- AI Extraction: Use AI to analyze layout and extract structured content
- Select a chunking method:
- By Document: Keep entire documents together
- By Page: Split content page by page
- By Section: Split by headers and sections
- By Keywords: Split when specified keywords are found
- Semantic: AI-powered semantic chunking
- Click "Scrape" to start the process.
The scraped data will appear in the table on the right. You can view the full API response by clicking "View API Response" or download all chunks as a ZIP file.
Structured Extraction
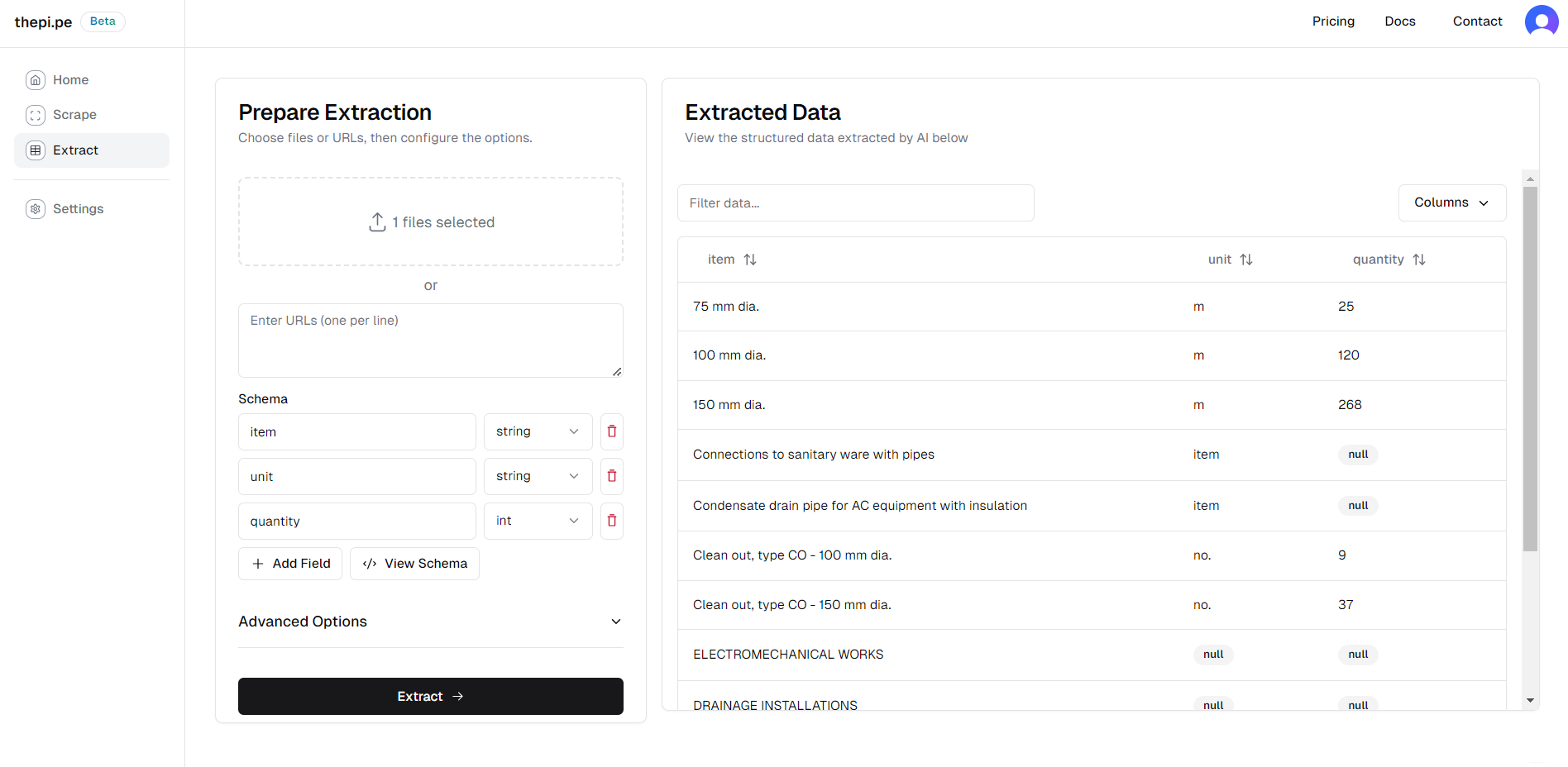
The extraction interface helps you extract structured data from your scraped content using Google Gemini 2.5 Flash Lite.
- Upload files or enter URLs as in the scraping interface.
- Define your schema:
- Add fields and specify their types (string, int, float, bool, date)
- Use recent schemas from previous extractions
- Fields are processed in the order you define them
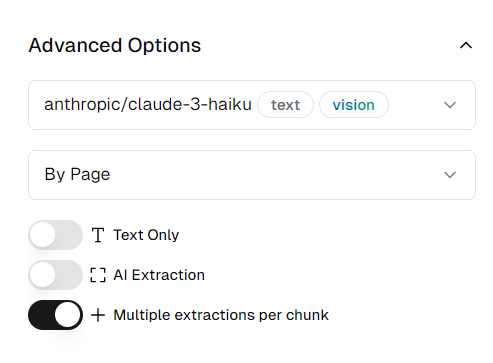
- Configure advanced options:
- Choose a chunking method (each chunk will be processed by the AI model)
- Enable/disable Text Only and AI Extraction
- Add custom prompts for specific extraction instructions
- Configure keyword-based chunking if needed
- Click "Extract" to start the process.
The extracted data will appear in the table on the right. You can download the results as a CSV file.

Double Check Feature
The platform includes an AI-powered double check feature that helps ensure extraction accuracy:
- After extraction completes, click "Double Check" to analyze the results
- The AI will review the extraction and suggest potential missed data
- Review the suggestions and select which ones to apply
- Choose whether to merge changes with existing data or append them
- Click "Apply Selected Changes" to update your extraction
This feature provides a human-in-the-loop workflow for mission-critical data extraction.
Schema Management
- Recent Schemas: Access previously used schemas from the dropdown
- Field Types: Support for strings, integers, floats, booleans, and dates
- Custom Prompts: Add specific instructions for domain-specific extractions
- Export Options: Download results as CSV for further analysis
Job History
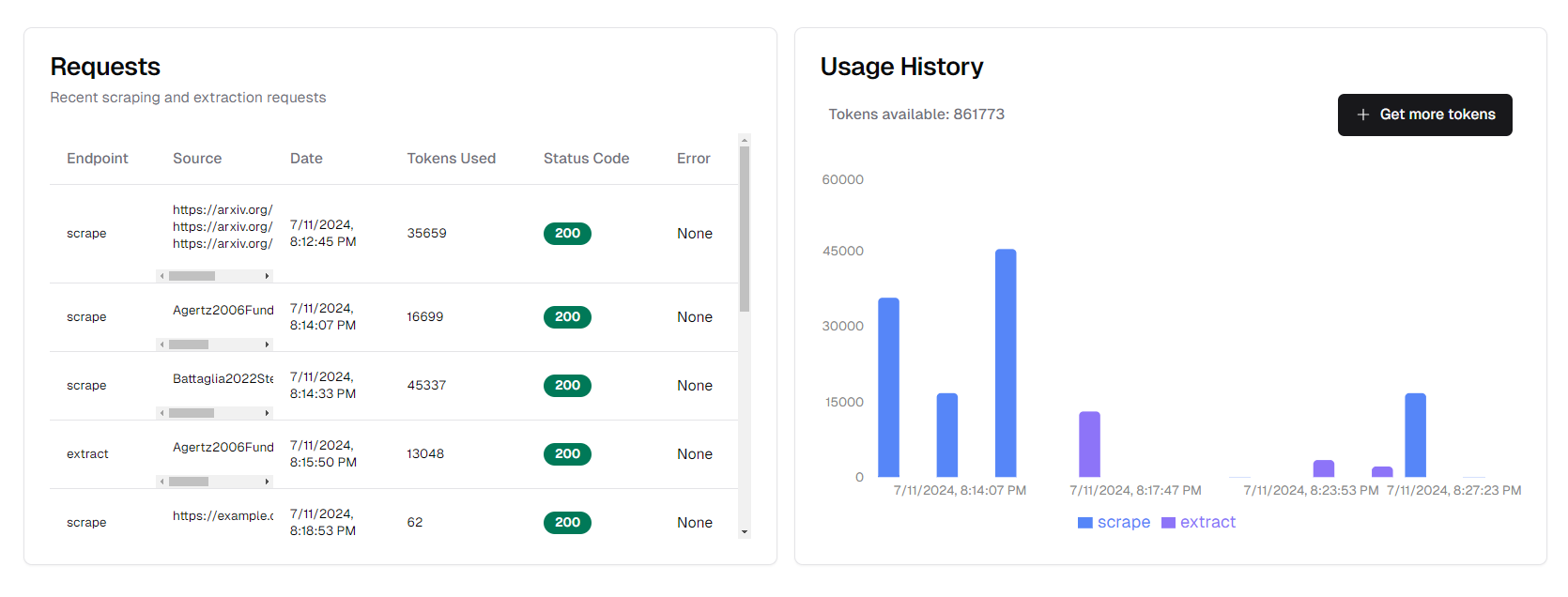
The job history section in the dashboard shows your recent scraping and extraction jobs. For each job, you can see:
- Endpoint used (scrape or extract)
- Source (file or URL)
- Date and time
- Tokens used
- Status code
- Any errors encountered
Supported File Types
The platform supports a wide variety of file types:
- Documents: PDF, Word (.docx, .doc), PowerPoint (.pptx, .ppt)
- Images: JPG, PNG, GIF, and other common formats
- Spreadsheets: Excel (.xlsx, .xls), CSV
- Media: Videos (MP4, MOV, AVI), Audio (MP3, WAV)
- Web: Any public webpage or URL
- Code: Jupyter notebooks (.ipynb), text files
- Archives: ZIP files containing supported formats
Chunking Strategies
Choose the appropriate chunking method based on your use case:
- By Document: Best for small documents or when you want to keep content together
- By Page: Ideal for PDFs and paginated documents
- By Section: Good for documents with clear section headers
- By Keywords: Useful when you want to split on specific terms
- Semantic: AI-powered chunking that groups related content together
API Integration
While the platform provides a user-friendly interface, you can also integrate thepi.pe directly into your applications using our API.
Authentication
Use your key from the platform settings as the API key:
curl -X POST "https://api.thepi.pe/extract" \
-H "Authorization: Bearer YOUR_API_KEY" \
-F "files=@document.pdf" \
-F "schema={\"name\":\"string\",\"price\":\"float\"}"For questions or support:
Email: emmett@thepi.pe
GitHub: github.com/emcf/thepipe
Platform settings for account management